Abstract
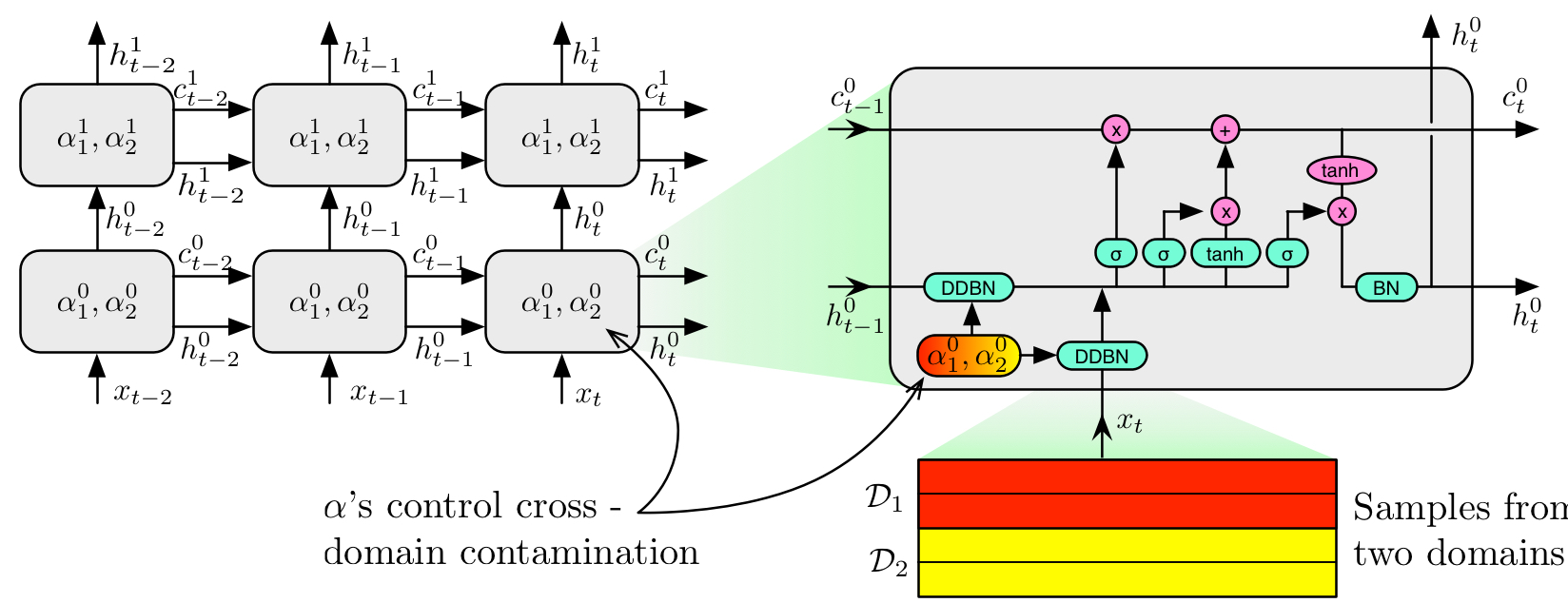
Domain alignment in convolutional networks aims to learn the degree of layer-specific feature alignment beneficial to the joint learning of source and target datasets. While increasingly popular in convolutional networks, there have been no previous attempts to achieve domain alignment in recurrent networks. Similar to spatial features, both source and target domains are likely to exhibit temporal dependencies that can be jointly learnt and aligned.
In this paper we introduce Dual-Domain LSTM (DDLSTM), an architecture that is able to learn temporal dependencies from two domains concurrently. It performs cross-contaminated batch normalisation on both input-to-hidden and hidden-to-hidden weights, and learns the parameters for cross-contamination, for both single-layer and multi-layer LSTM architectures. We evaluate DDLSTM on frame-level action recognition using three datasets, taking a pair at a time, and report an average increase in accuracy of 3.5%. The proposed DDLSTM architecture outperforms standard, fine-tuned, and batch-normalised LSTMs.
Video
Paper
Bibtex
@InProceedings{perrettdamen19ddlstm,
author = {Perrett, Toby and Damen, Dima},
title = {DDLSTM: Dual-Domain LSTM for Cross-Dataset Action Recognition},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2019}
}
Acknowledgements
This research is supported by EPSRC LOCATE (EP/N033779/1).